Accelerating DSP: SIMD Optimization for FIR Filters
February 17, 2026 · Luciano Muratore
I am still learning how to optimize the CPU for DSP, and one of the most powerful tools available is SIMD (Single Instruction, Multiple Data).
Modern CPUs can process multiple floating-point values at once. This is crucial in Signal Processing, where we frequently apply the same mathematical operation to a long stream of samples.
FIR vs. IIR: The Parallel Advantage
The FIR (Finite Impulse Response) filter is a perfect candidate for SIMD acceleration. In an FIR filter, each output sample depends only on the current and previous input samples—not on previous output samples.
Because the data is independent, we can process chunks of samples simultaneously. This is a contrast to IIR (Infinite Impulse Response) filters, where the feedback loop creates a dependency on the previous output, making basic parallelization difficult.
Note: While harder, it isn’t impossible. There is an interesting paper titled “Parallelization of IIR Filters using SIMD Extension” that explains how to leverage SIMD even for recursive filters.
Performance Comparison
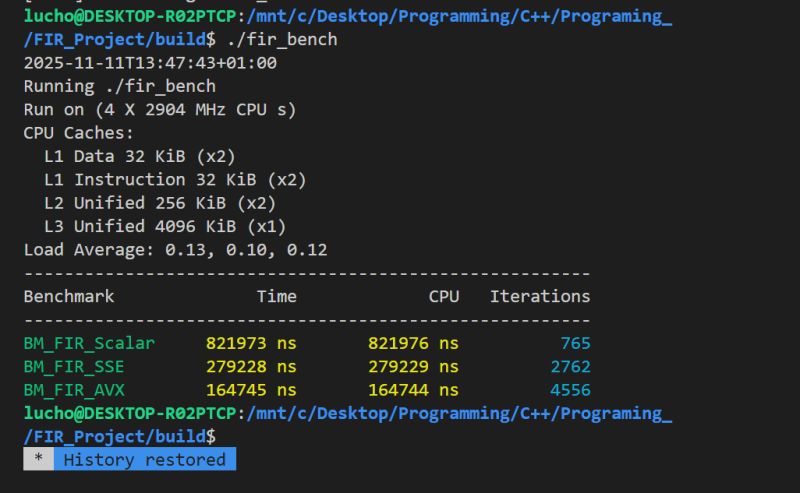
Below is a comparison showing the execution speed across different implementation methods:
- Scalar: A regular C++ loop (one sample at a time).
- SSE: 128-bit SIMD Intrinsics (4 samples per instruction).
- AVX: 256-bit SIMD Intrinsics (8 samples per instruction).
Source Code
You can find the implementation and benchmarks in my repository here: GitHub Repo: SIMD-DSP-Examples